머신러닝 프로젝트의 처음부터 끝까지
1. 큰그림을 본다.
2. 데이터를 구한다.
3. 데이터를 탐색하고 시각화한다.
4. 데이터를 준비한다.
5. 모델을 선택하고 훈련한다.
6. 모델을 상세하게 조정한다.
7. 솔루션을 제시한다.
8. 시스템을 런칭하고 유지보수한다.
추천 데이터 저장소
- UC 얼바인lrvine 머신러닝 저장소 (http://archive.ics.edu/ml)
- 캐글kaggle 데이터셋 (http://www.kaggle.com/datasets)
- 아마존 aws 데이터셋 https://registry.opendata.aws
- 데이터 포털 http://opendatamonitor.eu
- 퀸들Quandl http://quandl.com
- 위키백과 머신러닝 데이터셋 목록 https://goo.gl/SJHN2k
- Quora.com https://homl.info/0
- 데이터셋 서브레딧 http://www.reddit.com/r/datasets
캘리포니어 주택 가격 데이터셋 설명 :
캘리포니어 블록 그룹 마다 인구, 중간 소득, 중간 주택 가격 등을 담고 있는 데이터셋이다.
2.2.1 문제정의
'비즈니스의 목적이 정확히 무엇인가?'
목적을 아는것 -> 문제 구성, 알고리즘 선택, 모델 평가의 성능지표, 모델의 정확성 등을 결정
머신러닝 파이프라인 :
데이터처리 컴포넌트 + 데이터 저장소로 구성되고,
각 컴포넌트는 비동기적으로 수행되고, 완전히 독립적이다.
컴포넌트는 데이터를 추출해 자신의 출력 결과를 만들고, 데이터 저장소에 저장한다.
따라서 한 컴포넌트가 다운되더라도, 이후 컴포넌트는 다운된 컴포넌트의 마지막 출력을 이용해서 계속 동작할 수 있다.
'현재 솔루션은 어떻게 구성되어 있나요?'
현재 상황은 문제 해결방법에 대한 정보, 참고 성능으로도 사용될 수 있음
'문제 정의'
ex 인구조사 데이터 : 수천개의 중간 주택 가격 + 다른 데이터들
레이블 된 데이터 존재 : 지도 학습
값을 예측 : 회귀
예측에 사용할 특성이 여러개 : 다중 회귀
각 구역마다 하나의 값을 예측 : 단변량 회귀univariate regression
각 구역마다 여러개의 값을 예측 : 다변량 회귀multivariate regression
시스템으로 들어오는 데이터에 연속적인 흐름이 없음 + 빠르게 적응 하지 않아도됨 +
+ 데이터가 메모리에 들어갈만큼 작음 : 배치 학습
2.2.2 성능 측정 지표 선택
일반적인 회귀 문제의 전형적인 성능지표 : 평균 제곱근 오차root mean square error RMSE
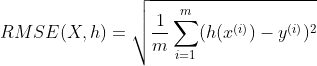
# \(m\) : 데이터 셋의 샘플수
# \(\textbf{x}^{(i)}\) : 데이터 셋에 있는 i 번째 샘플, 전체 특성값 벡터
# \(y^{(i)}\) : 해당 레이블, 해당 샘플의 기대 출력값
# \(X\) : 모든 \(\textbf{x}^{(i)}\) 를 행으로 가진 행렬
# \(h\) : 시스템의 예측함수, 가설hypothesis라고도 함, \(\hat{y} = h(\textbf{x}^{(i)})\) 예측값을 출력함.
평균 제곱근 오차RMSE는 선호되지만 경우에 따라 다른함수를 사용가능하다.
평균 절대 오차mean absolute error(평균 절대 편차mean absolute deviation)
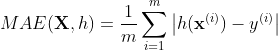
RMSE, MAE 모두 예측값 벡터와, 타깃값 벡터의 거리를 측정하는 방식이다.
거리 측정에는 여러가지 방법(norm)이 가능하다.
1. 제곱항을 합한것의 제곱근RMSE : 유클리디안 노름Euclidean norm, \(l_{2}\), \(\left \| \cdot \right \|\), \(\left \| \cdot \right \|_{2}\)
2. 절대값의 합 : 맨하튼 노름Manhattan norm, \(l_{2}\), \(\left \| \cdot \right \|_{1}\)
3. norm의 지수가 클수록 큰 값의 원소에 치우치며 작은값은 무시된다. 그래서 RMSE가 MAE보다 조금 더 이상치에 민감하다.
2.2.3 가정 검사
지금까지 만들어 놓은 가정을 나열하고 검사한다.
2.3 데이터 가져오기
실습 notebook
Google Colaboratory Notebook
Run, share, and edit Python notebooks
colab.research.google.com
계층적 샘플링stratified sampling
무작위 샘플링을 실시할경우 편향이 생길 가능성이 있다.
데이터에 남성이 48%, 여성이 52%라면, 구성된 샘플에서도 이 비율이 유지되어야 한다.
테스트 세트가 전체 데이터 세트를 대표하도록 각 계층에서 올바른 수의 샘플을 추출해야한다.
2.4 데이터이해를 위한 탐색과 시각화
데이터 셋의 특성들에 관한 표준 상관계수standard correlation coefficient
-1 ~ 1 의 범위를 가지고, 1에 가까울수록 양의 상관관계, -1에 가까울수록 음의 상관관계를 가진다.
2.5 머신러닝 알고리즘을 위한 데이터 준비
데이터 준비작업을 자동화 해야하는 이유
- 다양한 데이터셋에 대해서 데이터 변환을 쉽게 수행할 수 있다.
- 데이터 변환 라이브러리를 점진적으로 구축한다.
- 여러 가지 데이터 변환을 쉽게 시도할 수 있고, 다양한 데이터 조합을 쉽게 확인할 수 있다.
데이터 정제
머신러닝 특성상 누락된 데이터를 처리하지 못한다.
해결법
1. 해당 구역을 제거한다.
2. 전체 특성을 삭제한다.
3. 어떤 값으로 채운다.
범주형 혹은 텍스트 데이터를 숫자형 데이터로 변환시 문제점
10개의 카테고리를 0~9의 숫자로 지정하게되면,
머신러닝은 0과1의 관계를 0과4의 관계보다 더 가깝다고 인식한다.
이것은 오류를 범할 수 있기때문에, 원-핫 인코딩을 이용한다.
카테고리의 개수가 너무많아 원-핫 인코딩 사용시 성능의 저하가 우려될때.
관련된 숫자형 특성으로 변경하거나, 각 카테고리를 임베딩embedding이라 하는 학습가능한 저차원 벡터로 바꾼다.
이 임베딩 벡터를 훈련하면서 카테고리의 표현을 학습시킨다 -> 표현 학습representating learning
특성 스케일링
데이터 특성의 숫자 스케일이 다르면 잘 작동하지 않는다. 타깃값의 스케일링은 일반적으로 불필요하다.
-> 모든 특성의 범위가 같도록 만들어주는 방법 min-max스케일링, 표준화standardization
- min-max스케일링(정규화normalization)
특성이 0~1범위에 들도록 스케일을 조정한다. (각 값) - (min 값) / (max 값) - (min 값)
- 표준화
특성을 정규분포의 형태로 변환한다.
(각 값) - (평균) / (표준편차) : 하한과 상한이 정해지지않는다. 하지만 이상치에 영향을 덜받는다.
2.8 론칭, 모니터링, 시스템 유지 보수
시간이 지남에따라 모델도 낙후되는 경향이 있기때문에, 항상 실전 성능을 모니터링 해야한다.